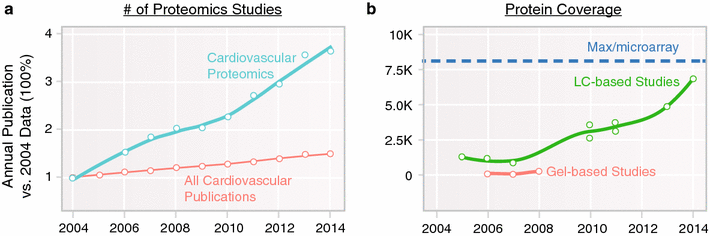
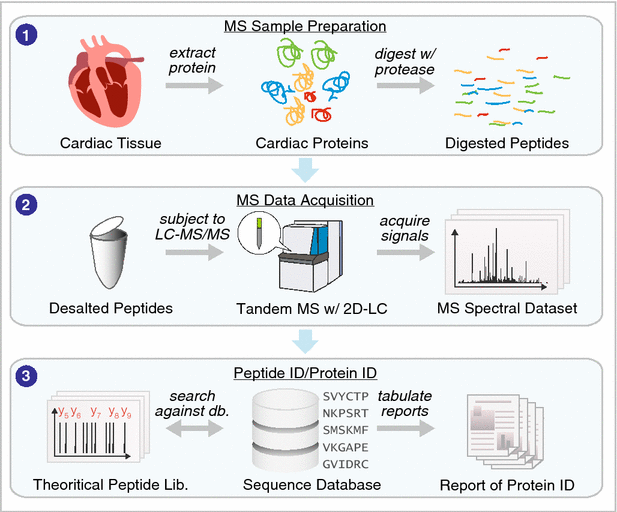
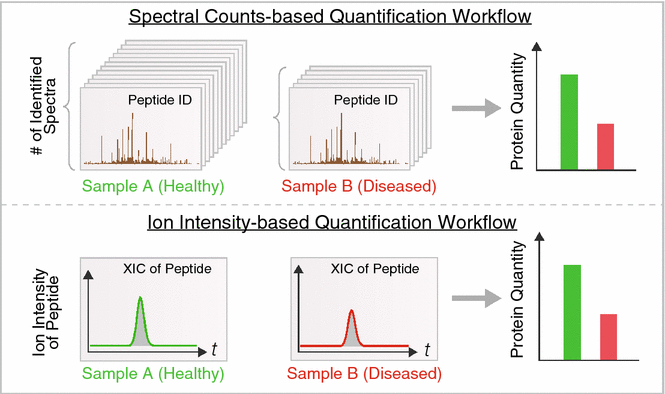
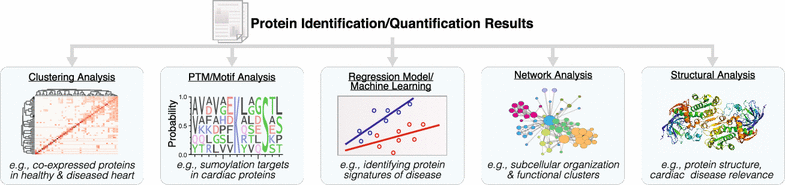
Plasma stability
In an ideal clinical world, when a blood sample is taken for biomarker research based on metabolomics or proteomics, it will remain stable until the analysis has taken place, making it easy to understand the conditions in the body when it was extracted. However, the real world is not ideal. A number of endogenous enzymes in blood immediately begin to degrade other proteins and peptides once it has left the body.
For plasma, which is the non-clotted fraction of blood, these processes are dampened by the addition of so-called anticoagulants which are added straight away. Sodium citrate, EDTA and heparin are commonly chosen examples. However, for serum, whole blood is allowed to clot naturally and the supernatant is retained, with no anticoagulants added.
The choice of plasma versus serum and the effects of different anticoagulants on clinical

Library collection
Serum and plasma were collected from a single man and the three aforementioned anticoagulants were added to different portions of the plasma. They were added to 512 well plates, each containing one of a specially constructed library of fluorogenic peptide probes to test the activity of the proteolytic enzymes.
These peptides contained different groups of amino acids plus a portion that emitted fluorescence under UV light at 320 nm. At the opposite end of the molecules to the fluorophores, on the other side of the amino acids, was a group based on dinitrophenyl-2,3-diaminopropionic acid which internally quenched the fluorescence. Only when the peptides were added to the samples, and the proteolytic peptides broke them apart, could the fluorescent parts emit light.
So, by careful selection of the amino acids in the library molecules, a whole range of proteolytic peptides could be targeted. For instance, trypsin and its relatives attack the lysine-arginine combination whereas other enzymes attack the bonds between proline and other amino acids. After suitable residence times, the wells were analysed by time-resolved fluorescence.
Proteolytic divergence
There were major differences in the proteolytic activities between the biofluids, which could lead to the selection of specific conditions for studies targeting particular biomarkers.
The least active of the four biofluids was plasma-EDTA which had a noticeably strong inhibitory effect on enzymes which target aromatic amino acids. This makes it the best choice for protein profiling studies involving techniques such as mass spectrometry in which the proteolytic activity must be restrained.
Plasma-citrate and plasma-heparin displayed similar levels of proteolytic activity, with citrate tending to attack bonds next to aliphatic amino acids and heparin phenylalanine-tyrosine bonds. The researchers recommended that plasma-citrate should be used for applications that study protease activity. Serum was found to be as active as plasma-citrate so could be used as an alternative.
About 38% of the peptides in the library were not cleaved at all, many of them containing proline or the aspartic acid-glutamic acid combination. These negative results might be helpful in the design of stable tags for drug delivery that would not become degraded in the blood stream.
Despite being taken from a single donor, the results should be viewed with some confidence, since the variations caused by sample preparation will be low, say the research duo. They will help scientists in the "omics" areas and biomarker studies to select the best medium for their work, so that the results are not compromised by the actions of the endogenous enzymes present in blood.